Nota de aplicação:
Pontuação de acessibilidade sintética (SAS) do Synthia
Avalie as Pontuações de acessibilidade sintética (SAS) de milhares de moléculas virtuais em minutos
Interconecte suas ferramentas de quiminformática com o Software de retrossíntese SYNTHIA®.
Acesso à API
O acesso à API (Interface de Programação de Aplicativos) está disponível para organizações que gostariam de interconectar outras ferramentas de quiminformática com o SYNTHIA® para obter uma experiência personalizada.
Os benefícios incluem:
- Acesso à retrosíntese completa ou à API de Pontuação de Acessibilidade Sintética (SAS)
- Visualização de dados lado a lado para melhorar os insights sobre a seleção de moléculas
- Criação de visualizações robustas usando várias fontes de dados
- Informações sobre a seleção de moléculas a montante da etapa de síntese
- Análise de milhares de vias em minutos com a API SAS
Aproveite o poder da Pontuação de Acessibilidade Sintética (SAS)
A capacidade de diferenciar entre moléculas "fáceis de criar" e "difíceis de criar" é uma tarefa difícil, mas amplamente útil, por exemplo, para priorizar compostos em pipelines de triagem virtual. Ao combinar o modelo moderno de aprendizagem profunda e os dados coletados com nosso renomado software de planejamento retrosintético, fornecemos o serviço de Pontuação de acessibilidade sintética (SAS) SYNTHIA®, uma ferramenta aplicável ao processamento de compostos in silico de alto rendimento.
Atualmente, a química combinatória e a modelagem generativa são usadas para construir conjuntos de dados de compostos gigantescos [1]. Entretanto, a síntese real de
muitas moléculas obtidas com esses métodos pode ser um desafio. Para resolver esse problema, as medidas de acessibilidade sintética são usadas para determinar a viabilidade da molécula o mais cedo possível no pipeline de descoberta de medicamentos.
O serviço SYNTHIA® API do SAS fornece as previsões para essa "complexidade molecular" em termos de número de etapas sintéticas de pequenos blocos de construção disponíveis comercialmente. O modelo de aprendizado de máquina subjacente ao SAS foi pré-treinado em cenários sintéticos obtidos com algoritmos da SYNTHIA® Retrosynthetic Planning Tool [2], [3], [4]. Por fim, nosso produto hospedado na nuvem e certificado pela ISO-27001 oferece a capacidade de processar facilmente milhões de moléculas diariamente e até mil moléculas em uma única consulta, permitindo que a previsão de serviços do SYNTHIA® SAS seja mais comumente usada no processo de design de medicamentos.
Entrada/saída para o modelo SAS
As moléculas de entrada precisam ser fornecidas no formato de texto SMILES amplamente utilizado [5] e o ponto de extremidade da API suporta solicitações em lote. O SMILES de entrada consiste em uma única molécula de fragmento. A medida retornada, aqui definida como Pontuação de acessibilidade sintética (SAS), é um único número flutuante no intervalo de 0 a 10, atribuído a cada molécula de entrada correspondente. A pontuação retornada indica quantas etapas são necessárias para sintetizar a molécula usando Blocos de construção disponíveis comercialmente. Os números mais baixos (valores próximos a 0) são retornados para produtos químicos que se prevê serem fáceis de fabricar (ou que podem até estar disponíveis comercialmente). Os números mais altos são retornados quando o modelo prevê mais etapas sintéticas para obter o composto solicitado. Para pontuações próximas ao valor máximo (10), prevê-se que a síntese seja extremamente complexa (muitas etapas de reação) ou até mesmo inviável, por exemplo, devido a motivos estruturais exóticos na molécula. Em geral, quanto menor a pontuação, mais fácil deve ser sintetizar a molécula.
Caso algumas das moléculas solicitadas sejam inválidas (por exemplo, hipervalentes, anéis incompletos, protonação inadequada de átomos aromáticos, multifragmentos), a solicitação ainda será processada. As pontuações para essas entradas serão nulas e os comentários apropriados serão retornados ao lado da estrutura de resposta.
Características do modelo preditivo
O SYNTHIA® SAS v1.0 é baseado em um regressor que inclui uma rede neural convolucional gráfica (GCNN). Essa arquitetura permite o aprendizado de uma representação interna de cada molécula operando em sua estrutura gráfica em vez de descritores moleculares pré-computados [6]. Em particular, o modelo consiste em uma rede neural de passagem de mensagem dirigida em nível de ligação (D-MPNN) seguida por uma rede neural de avanço (FNN). A implementação foi adaptada do projeto de código aberto Chemprop [7].
O modelo de aprendizado de máquina foi treinado usando os resultados do módulo de Retrossíntese automática SYNTHIA® como um valor-alvo. A pontuação SYNTHIA® especializada e normalizada foi usada para refletir o número de etapas, por exemplo, não penalizando reações não seletivas, estratégia de proteções implícitas, contribuição mínima de preço para a pontuação e apenas pequenos Blocos de construção foram usados como configurações de pesquisa SYNTHIA®. Além disso, uma função de suavização foi aplicada para criar um gradiente melhor para pontuações altas, visando a uma melhor resolução de moléculas difíceis de sintetizar (consulte também a Fig. 1).
Os dados usados para o treinamento de modelos de aprendizado de máquina têm 33.306 moléculas no total. Eles são compostos de moléculas conhecidas (banco de dados ChEMBL) [8] e moléculas pequenas geradas combinatoriamente (GDB) [9]. A composição dos dados antes da divisão treinamento/teste:
- Subconjunto GDB: 16081, incluindo:
- compostos com 1-7 átomos pesados (C, N, O, Cl, S): 7198
- compostos com 8-9 átomos pesados (C, N, O): 8883
- subconjunto ChEMBL: 17225, incluindo:
- pequenos compostos sintéticos selecionados aleatoriamente: 15449
- compostos derivados de produtos naturais selecionados aleatoriamente: 1776
O treinamento e a avaliação do modelo de aprendizado de máquina exigiram a divisão dos dados em conjuntos de treinamento e teste (foi usada uma divisão comum de 80/20 entre treinamento e teste). Além disso,
o conjunto de validação interna foi extraído usando a proporção de 9:1 do conjunto de treinamento e foi usado para a otimização dos parâmetros da rede.
A pontuação prevista (modelo SYNTHIA® SAS) está correlacionada com o valor-alvo com base nas pontuações SYNTHIA® com R2 = 0,726 e MAE = 1,1497. O gráfico de dispersão com a linha ajustada e o gráfico de caixa mostrando a densidade/distribuição dos pontos de dados são apresentados na Fig. 2.

Os resultados previstos com o SYNTHIA® SAS baseiam-se em relações recuperadas de conjuntos de dados (possivelmente, bastante complexos e difíceis de capturar). Isso deve ser levado em consideração quando moléculas novas são consultadas por meio do SYNTHIA® SAS-API. Ou seja, as pontuações das moléculas que não estão relacionadas ao conjunto de teste podem ficar fora do chamado domínio de aplicabilidade e, portanto, os resultados correspondentes podem não ser significativos. Essa é uma limitação típica dos modelos orientados por dados; no entanto, é sempre bom lembrar essa limitação para evitar interpretações errôneas das pontuações obtidas.
Estudos de caso
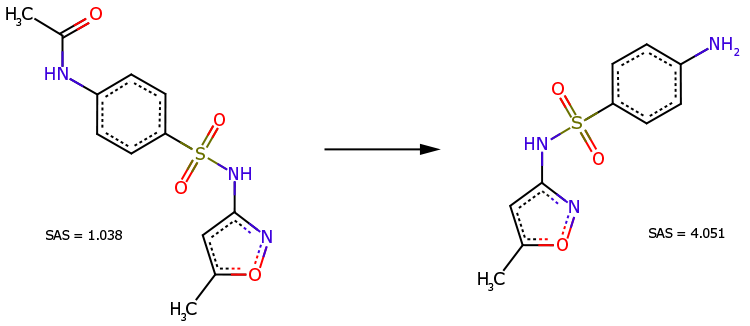
Caso 1
O derivado N-acetil do sulfametoxazol (Fig. 3, à esquerda) é um precursor direto desse medicamento (Fig. 3, à direita). Apesar da estrutura química mais complexa, o derivado é reconhecido como mais fácil de sintetizar (SAS=1,038 é muito menor do que SAS=4,051).
Caso 2
Por outro lado, o derivado N-Boc da adrenalina (Fig. 4, à esquerda) não é um precursor direto da adrenalina (Fig. 4, à direita). Em um procedimento típico, não há necessidade de proteger o grupo amino em todo o caminho da síntese. O derivado N-Boc é corretamente reconhecido como mais complexo em termos de acessibilidade sintética (SAS = 8,399 é maior do que SAS = 7,631). Isso está de acordo com o fato de que a adrenalina é um precursor de seu derivado N-Boc.

Fluxo de dados do usuário
O SYNTHIA® API é um serviço hospedado na nuvem, disponível para cada cliente por meio da API RESTful. Ele é horizontalmente dimensionável e oferece Alto rendimento por meio de um único ponto de entrada de API para todos os clientes. O usuário final precisa fornecer uma lista de moléculas em um formato SMILES e o SYNTHIA® SAS retorna uma pontuação para cada uma delas (Fig. 5). O serviço é sem estado e foi projetado para ser dimensionado de acordo com a demanda.

Referências
1. Joshua Meyers, Benedek Fabian, Nathan Brown, De novo molecular design and generative models, Descoberta de medicamentos Today, 26, 2021, 2707-2715. DOI
2.Software de retrossíntese SYNTHIA®
3.Tomasz Klucznik, et al., Eficiência na síntese de alvos diversos e medicamente relevantes planejados por computador e executados em laboratório, Chem, 4, 2018,
522-532.DOI
4. Mikulak-Klucznik, B., et al. Planejamento computacional da síntese de produtos naturais complexos, Nature, 588, 2020, 83-88. DOI
5.Daylight Chemical Information Systems, Inc.
6. Yang, K., et al. Analyzing Learned Molecular Representations for Property Prediction, Journal of chemical information and modeling, 59, 2019, 3370-3388. DOI
7.Projeto de código aberto Chemprop
8.Banco de dados ChEMBL
9.Banco de dados GDB
