Catatan Aplikasi:
Skor Aksesibilitas Sintetis Synthia (SAS)
Menilai skor aksesibilitas sintetis (SAS) dari ribuan molekul virtual dalam hitungan menit
Hubungkan Alat Cheminformatika Anda dengan Perangkat LunakRetrosintesis SYNTHIA®
Akses API
Akses API (Antarmuka Pemrograman Aplikasi) tersedia bagi organisasi yang ingin menghubungkan alat Cheminformatika lainnya dengan SYNTHIA® untuk pengalamanyang disesuaikan.
Manfaat Termasuk:
- Akses retrosintesis penuh atau Skor Aksesibilitas Sintetis (SAS) API
- Lihat data secara berdampingan untuk meningkatkan wawasan tentang pemilihan molekul
- Buat visualisasi yang kuat menggunakan berbagai sumber data
- Menginformasikan pemilihan molekul di bagian hulu dari langkah sintesis
- Menganalisis ribuan jalur dalam hitungan menit dengan SAS API
Memanfaatkan kekuatan Skor Aksesibilitas Sintetis (SAS)
Kemampuan untuk membedakan antara molekul yang 'mudah dibuat' dan 'sulit dibuat' adalah tugas yang sulit, tetapi sangat berguna, misalnya, untuk memprioritaskan senyawa dalam jalur skrining virtual. Dengan menggabungkan model deep-learning modern, dan data yang dikumpulkan dengan perangkat lunak perencanaan retrosintetik kami yang terkenal, kami memberikan layanan SYNTHIA® Skor AksesibilitasSintetis (SAS), sebuah alat yang dapat digunakan untuk pemrosesan senyawa in-silico dengan Kapasitas Tinggi.
Saat ini, kimia kombinatorial dan pemodelan generatif digunakan untuk membangun kumpulan data senyawa raksasa [1]. Namun, sintesis aktual
banyak molekul yang diperoleh dengan metode tersebut mungkin menantang. Untuk mengatasi masalah ini, langkah-langkah aksesibilitas sintetis digunakan untuk menentukan kelayakan molekul sedini mungkin dalam proses Penemuan Obat.
LayananSYNTHIA® SAS API menyediakan prediksi untuk 'kompleksitas molekuler' seperti itu dalam hal jumlah langkah sintetis dari bahan penyusun kecil yang tersedia secara komersial. Model pembelajaran mesin yang mendasari SAS telah dilatih sebelumnya pada skenario sintetis yang diperoleh dengan algoritme dariSYNTHIA® Retrosynthetic Planning Tool [2], [3], [4]. Terakhir, Produk kami yang di-host di cloud dan bersertifikasi ISO-27001 menawarkan kemampuan untuk dengan mudah memproses jutaan molekul setiap hari dan hingga seribu molekul dalam satu kueri, sehingga memungkinkan prediksilayanan SYNTHIA® SAS lebih umum digunakan dalam proses desain obat.
Masukan/keluaran untuk model SAS
Molekul input harus disediakan dalam format teks SMILES yang digunakan secara luas [5] dan titik akhir API mendukung permintaan batch. SMILES masukan terdiri dari molekul fragmen tunggal. Ukuran yang dikembalikan, di sini didefinisikan sebagai Skor Aksesibilitas Sintetis (SAS), adalah angka float tunggal dari rentang 0-10, yang ditetapkan untuk setiap molekul input yang sesuai. Skor yang dikembalikan memperkirakan berapa banyak langkah yang diperlukan untuk mensintesis molekul menggunakan bahan penyusun yang tersedia secara komersial. Angka terendah (nilai mendekati 0) dikembalikan ke bahan kimia yang diprediksi mudah dibuat (atau bahkan dapat tersedia secara komersial). Angka yang lebih tinggi dikembalikan ketika model memperkirakan lebih banyak langkah sintetis untuk mendapatkan senyawa yang diminta. Untuk nilai yang mendekati nilai maksimal (10), sintesis diperkirakan akan menjadi sangat kompleks (banyak langkah reaksi) atau bahkan tidak layak, misalnya, karena motif struktural yang eksotis dalam molekul. Secara umum, semakin rendah skornya, semakin mudah untuk mensintesis molekul tersebut.
Dalam Acara di mana beberapa molekul yang diajukan tidak valid (misalnya, hipervalen, cincin yang tidak lengkap, protonasi atom aromatik yang tidak tepat, multi-fragmen), permintaan akan tetap diproses. Nilai untuk entri tersebut akan menjadi nol dan komentar yang sesuai akan dikembalikan bersamaan dengan struktur respons.
Karakteristik model prediktif
SYNTHIA® SAS v1.0 didasarkan pada regressor yang mencakup graph convolutional neural network (GCNN). Arsitektur tersebut memungkinkan untuk mempelajari representasi internal dari setiap molekul dengan beroperasi pada struktur grafiknya daripada deskriptor molekul yang telah dihitung sebelumnya [6]. Secara khusus, model ini terdiri dari jaringan saraf pengirim pesan terarah tingkat ikatan (D-MPNN) yang diikuti oleh jaringan saraf umpan maju (FNN). Implementasi ini diadaptasi dari proyek sumber terbuka Chemprop [7].
Model pembelajaran mesin dilatih menggunakan hasil modul Synthesis Retrosecara Otomatis SYNTHIA® sebagai nilai target.Skor SYNTHIA® yang dikhususkan dan dinormalisasi digunakan untuk mencerminkan jumlah langkah, misalnya, tidak menghukum reaksi non-selektif, strategi perlindungan implisit, kontribusi harga minimal terhadap skor, dan hanya bahan penyusun kecil yang digunakan sebagai pengaturan pencarian SYNTHIA®. Selain itu, fungsi penghalusan diterapkan untuk membangun gradien yang lebih baik untuk skor tinggi, yang bertujuan untuk resolusi yang lebih baik dari molekul yang sulit untuk disintesis (lihat juga Gbr. 1).
Data yang digunakan untuk pelatihan model pembelajaran mesin memiliki total 33.306 molekul. Data ini terdiri dari molekul yang diketahui (database ChEMBL) [8] dan molekul kecil yang dihasilkan secara kombinatorial (GDB) [9]. Komposisi data sebelum pemisahan pelatihan/pengujian:
- subset GDB: 16081, termasuk:
- senyawa dengan 1-7 atom berat (C, N, O, Cl, S): 7198
- senyawa dengan 8-9 atom berat (C, N, O): 8883
- Subset ChEMBL: 17225, termasuk:
- senyawa kecil sintetis yang dipilih secara acak: 15449
- senyawa turunan Produk alami yang dipilih secara acak: 1776
Pelatihan dan evaluasi model pembelajaran mesin membutuhkan pemisahan data menjadi set pelatihan dan pengujian (pemisahan pelatihan / pengujian 80/20 yang umum digunakan). Selanjutnya,
set validasi internal diekstraksi menggunakan rasio 9:1 dari set pelatihan dan digunakan untuk optimasi parameter jaringan.
Skoryang diprediksi (model SYNTHIA® SAS) berkorelasi dengan nilai targetberdasarkan skor SYNTHIA® dengan R2 = 0,726 dan MAE = 1,1497. Scatter plot dengan fitted line dan box plot yang menunjukkan kepadatan/distribusi titik-titik data, disajikan pada Gbr. 2.

Hasil yang diprediksi denganSYNTHIA® SAS didasarkan pada hubungan yang diambil dari kumpulan data (mungkin, cukup kompleks dan tidak mudah untuk ditangkap). Hal ini harus dipertimbangkan ketika molekul baru ditanyakan melaluiSYNTHIA® SAS-API. Yaitu, skor untuk molekul yang tidak terkait dengan set pengujian mungkin keluar dari apa yang disebut domain penerapan, oleh karena itu hasil yang sesuai mungkin tidak bermakna. Ini adalah batasan umum untuk model berbasis data, namun demikian, selalu baik untuk mengingat batasan tersebut untuk menghindari salah tafsir skor yang diperoleh.
Studi kasus
Kasus 1
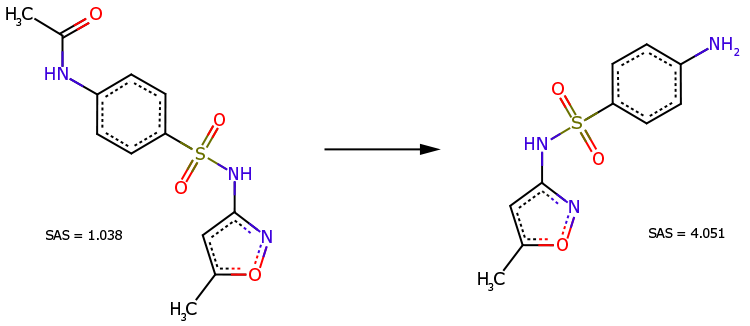
Turunan n-asetil dari sulfametoksazol (Gbr. 3, kiri) adalah prekursor langsung dari obat ini (Gbr. 3, kanan). Meskipun struktur kimianya lebih kompleks, turunannya diakui lebih mudah untuk disintesis (SAS = 1,038 jauh lebih kecil dari SAS = 4,051).
Kasus 2
Di sisi lain, turunan N-Boc dari adrenalin (Gbr. 4, kiri) bukan merupakan prekursor langsung dari adrenalin (Gbr. 4, kanan). Dalam prosedur umum, tidak perlu melindungi gugus amino di sepanjang jalur sintesis. Turunan N-Boc secara tepat dikenali sebagai lebih kompleks dalam hal aksesibilitas sintetis (SAS = 8,399 lebih besar dari SAS = 7,631). Hal ini sejalan dengan fakta bahwa adrenalin adalah prekursor turunan N-Boc.

Aliran Data Pengguna
SYNTHIA® SAS adalah layanan yang di-host di cloud, tersedia untuk setiap pelanggan melalui RESTful API. Layanan ini dapat diskalakan secara horizontal dan menyediakan kapasitas tinggi melalui satu titik masuk API untuk semua pelanggan. Pengguna akhir perlu memberikan daftar molekul dalam format SMILES danSYNTHIA® SAS mengembalikan skor untuk masing-masing molekul (Gbr. 5). Layanan ini tidak memerlukan biaya dan dirancang untuk menyesuaikan dengan permintaan.

Referensi
1. Joshua Meyers, Benedek Fabian, Nathan Brown, Desain molekuler de novo dan model generatif, Penemuan Obat Hari Ini, 26, 2021, 2707-2715. DOI
2.Perangkat LunakRetrosintesis SYNTHIA®
3.Tomasz Klucznik, dkk., Sintesis yang Efisien dari Target yang Beragam dan Relevan Secara Medis yang Direncanakan oleh Komputer dan Dieksekusi di Laboratorium, Chem, 4, 2018,
522-532. DOI
4.Mikulak-Klucznik, B., dkk. Perencanaan komputasi sintesis produk alami yang kompleks, Nature, 588, 2020, 83-88. DOI
5.Daylight Chemical Information Systems, Inc.
6. Yang, K., dkk. Menganalisis Representasi Molekuler yang Dipelajari untuk Prediksi Properti, Jurnal Informasi dan Pemodelan Kimia, 59, 2019, 3370-3388. DOI
7.Proyek sumber terbuka Chemprop
8.Basis data ChEMBL
9.Basis data GDB
