Nota de aplicação:
Pontuação de acessibilidade sintética (SAS) Synthia
Pontuação de acessibilidade sintética (SAS) de milhares de moléculas virtuais em minutos
Interligue as suas ferramentas de quiminformática com o Software de retrosíntese SYNTHIA®
Acesso API
O acesso à API (Interface de Programação de Aplicativos) está disponível para organizações que gostariam de interconectar outras ferramentas de Cheminformatics com SYNTHIA® para uma experiência personalizada.
Os benefícios incluem:
- Aceder à retrosíntese completa ou à API de Pontuação de acessibilidade sintética (SAS)
- Visualizar dados lado a lado para melhorar a perceção da seleção de moléculas
- Criar visualizações robustas utilizando várias fontes de dados
- Informar a seleção de moléculas a montante do passo de síntese
- Analisar milhares de vias em minutos com a API SAS
Aproveitar o poder da Pontuação de Acessibilidade Sintética (SAS)
A capacidade de diferenciar entre moléculas "fáceis de fazer" e "difíceis de fazer" é uma tarefa difícil, mas amplamente útil, por exemplo, para priorizar compostos em pipelines de triagem virtual. Combinando o modelo moderno de aprendizagem profunda e os dados recolhidos com o nosso famoso software de planeamento retrosintético, fornecemos o serviço de Pontuação de acessibilidade sintética (SAS) SYNTHIA®, uma ferramenta aplicável ao processamento de compostos in silico de alto rendimento.
Atualmente, a química combinatória e a modelação generativa são utilizadas para construir conjuntos de dados de compostos gigantescos [1]. No entanto, a síntese efectiva de
muitas moléculas obtidas com esses métodos pode ser um desafio. Para resolver este problema, são utilizadas medidas de acessibilidade sintética para determinar a viabilidade de uma molécula o mais cedo possível na cadeia de descoberta de medicamentos.
O serviço SYNTHIA® API SAS fornece as previsões para essa "complexidade molecular" em termos de número de etapas sintéticas a partir de pequenos Blocos de construção comercialmente disponíveis. O modelo de aprendizagem automática subjacente ao SAS foi previamente treinado em cenários sintéticos obtidos com algoritmos da SYNTHIA® Retrosynthetic Planning Tool [2], [3], [4]. Por último, o nosso produto alojado na nuvem e com certificação ISO-27001 oferece a capacidade de processar facilmente milhões de moléculas diariamente e até mil moléculas numa única consulta, permitindo que a previsão de serviços SYNTHIA® SAS seja mais frequentemente utilizada no processo de conceção de medicamentos.
Entrada/saída para o modelo SAS
As moléculas de entrada têm de ser fornecidas no formato de texto SMILES amplamente utilizado [5] e o ponto final da API suporta pedidos em lote. As SMILES de entrada consistem numa molécula de fragmento único. A medida devolvida, aqui definida como Pontuação de acessibilidade sintética (SAS), é um número flutuante único do intervalo 0-10, atribuído a cada molécula de entrada correspondente. A pontuação devolvida aproxima-se do número de passos necessários para sintetizar a molécula utilizando Blocos de construção comercialmente disponíveis. Os números mais baixos (valores próximos de 0) são devolvidos aos produtos químicos que se prevê serem fáceis de fabricar (ou mesmo que possam estar disponíveis comercialmente). Os números mais altos são devolvidos quando o modelo prevê mais etapas sintéticas para obter o composto solicitado. Para pontuações próximas do valor máximo (10), prevê-se que a síntese seja extremamente complexa (muitas etapas de reação) ou mesmo inviável, por exemplo, devido a motivos estruturais exóticos na molécula. Em geral, quanto mais baixa for a pontuação, mais fácil deverá ser sintetizar a molécula.
No caso de algumas das moléculas no pedido serem inválidas (por exemplo, hipervalentes, anéis incompletos, protonação incorrecta de átomos aromáticos, multi-fragmentos), o pedido será processado na mesma. As pontuações para essas entradas serão nulas e os comentários apropriados serão devolvidos juntamente com a estrutura da resposta.
Caraterísticas do modelo preditivo
O SYNTHIA® SAS v1.0 baseia-se num regressor que inclui uma rede neural convolucional gráfica (GCNN). Esta arquitetura permite aprender uma representação interna de cada molécula, operando na sua estrutura gráfica em vez de descritores moleculares pré-computados [6]. Em particular, o modelo consiste numa rede neural de passagem de mensagem dirigida (D-MPNN) a nível de ligação, seguida de uma rede neural de avanço (FNN). A implementação foi adaptada do projeto de código aberto Chemprop [7].
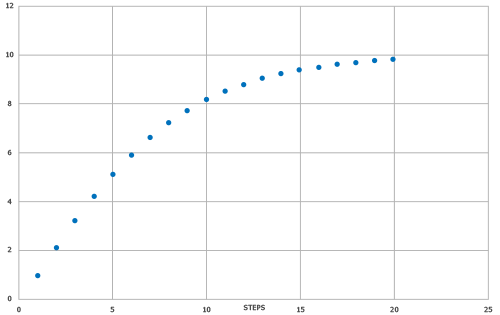
O modelo de aprendizagem automática foi treinado utilizando os resultados do módulo de Retrosíntese automática SYNTHIA® como valor alvo. Foi utilizada uma pontuação SYNTHIA® especializada e normalizada para refletir o número de etapas, por exemplo, não penalizando reacções não selectivas, estratégia de protecções implícitas, contribuição mínima do preço para a pontuação e apenas pequenos Blocos de construção foram utilizados como definições de pesquisa SYNTHIA®. Além disso, foi aplicada uma função de suavização para criar um gradiente mais adequado para pontuações elevadas, com o objetivo de melhorar a resolução de moléculas difíceis de sintetizar (ver também a Fig. 1).
Os dados utilizados para o treino dos modelos de aprendizagem automática têm um total de 33306 moléculas. São compostos por moléculas conhecidas (base de dados ChEMBL) [8] e por pequenas moléculas geradas combinatoriamente (GDB) [9]. A composição dos dados antes da divisão treino/teste:
- Subconjunto GDB: 16081, incluindo:
- compostos com 1-7 átomos pesados (C, N, O, Cl, S): 7198
- compostos com 8-9 átomos pesados (C, N, O): 8883
- Subconjunto ChEMBL: 17225, incluindo:
- pequenos compostos sintéticos selecionados aleatoriamente: 15449
- compostos derivados de produtos naturais selecionados aleatoriamente: 1776
O treino e a avaliação do modelo de aprendizagem automática exigiram a divisão dos dados em conjuntos de treino e de teste (foi utilizada uma divisão 80/20 comum entre treino e teste). Além disso,
o conjunto de validação interna foi extraído utilizando um rácio de 9:1 do conjunto de treino e foi utilizado para a otimização dos parâmetros da rede.
A pontuação prevista (modelo SYNTHIA® SAS) está correlacionada com o valor-alvo baseado nas pontuações SYNTHIA® com R2 = 0,726 e MAE = 1,1497. O gráfico de dispersão com a linha ajustada e o gráfico de caixa que mostra a densidade/distribuição dos pontos de dados são apresentados na Fig. 2.

Os resultados previstos com o SYNTHIA® SAS baseiam-se em relações obtidas a partir de conjuntos de dados (possivelmente, bastante complexos e não fáceis de captar). Este facto deve ser tido em consideração quando são consultadas moléculas novas através do SYNTHIA® SAS-API. Nomeadamente, as pontuações para moléculas que não estão relacionadas com o conjunto de teste podem ficar fora do chamado domínio de aplicabilidade, pelo que os resultados correspondentes podem não ser significativos. Trata-se de uma limitação típica dos modelos orientados por dados, mas é sempre bom recordar esta limitação para evitar interpretações erróneas das pontuações obtidas.
Estudos de casos
Caso 1
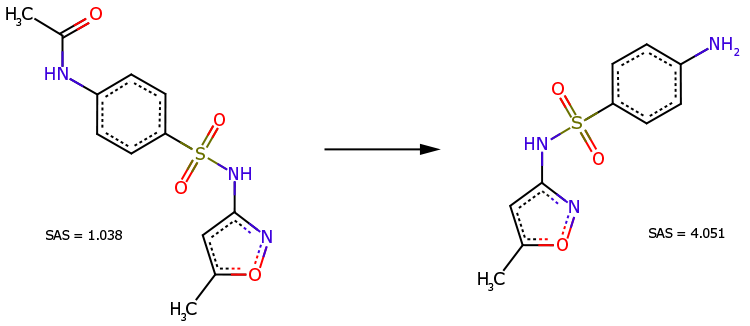
O derivado N-acetil do sulfametoxazol (Fig. 3, à esquerda) é um precursor direto deste fármaco (Fig. 3, à direita). Apesar da estrutura química mais complexa, o derivado é reconhecido como mais fácil de sintetizar (SAS=1,038 é muito mais pequeno do que SAS=4,051).
Caso 2
Por outro lado, o derivado N-Boc da adrenalina (Fig. 4, à esquerda) não é um precursor direto da adrenalina (Fig. 4, à direita). No procedimento típico, não há necessidade de proteger o grupo amino ao longo da via de síntese. O derivado N-Boc é corretamente reconhecido como mais complexo em termos de acessibilidade sintética (SAS=8,399 é superior a SAS = 7,631). Isto está de acordo com o facto de a adrenalina ser um precursor do seu derivado N-Boc.

Fluxo de dados do utilizador
O SYNTHIA® API é um serviço alojado na nuvem, disponível para cada cliente através de uma API RESTful. É horizontalmente escalável e fornece Alto rendimento através de um único ponto de entrada de API para todos os clientes. O utilizador final tem de fornecer uma lista de moléculas num formato SMILES e o SYNTHIA® SAS devolve uma pontuação para cada uma delas (Fig. 5). O serviço não tem estado e foi concebido para ser dimensionado de acordo com a procura.

Referências
1. Joshua Meyers, Benedek Fabian, Nathan Brown, Desenho molecular de novo e modelos generativos, Descoberta de medicamentos hoje, 26, 2021, 2707-2715. DOI
2.Software de retrosíntese SYNTHIA®
3.Tomasz Klucznik, et al., Sínteses com Eficiência de Alvos Diversos e Medicinalmente Relevantes Planeados por Computador e Executados no Laboratório, Chem, 4, 2018,
522-532.DOI
4. Mikulak-Klucznik, B., et al. Planeamento computacional da síntese de produtos naturais complexos, Nature, 588, 2020, 83-88. DOI
5.Daylight Chemical Information Systems, Inc.
6. Yang, K., et al. Analisando representações moleculares aprendidas para previsão de propriedades, Journal of chemical information and modeling, 59, 2019, 3370-3388. DOI
7.Projeto de código aberto Chemprop
8.Base de dados ChEMBL
9.Base de dados GDB
