Nota de aplicación:
Puntuación de accesibilidad sintética (SAS) de Synthia
Evalúe la Puntuación de accesibilidad sintética (SAS) de miles de moléculas virtuales en cuestión de minutos.
Interconecte sus herramientas de quimioinformática con el Software de retrosíntesis SYNTHIA
Acceso API
El acceso API (interfaz de programación de aplicaciones) está disponible para las organizaciones que deseen interconectar otras herramientas de quimioinformática con SYNTHIA® para disfrutar de una experiencia personalizada.
Las ventajas incluyen:
- Acceso completo a la API de retrosíntesis o de Puntuación de accesibilidad sintética (SAS)
- Visualización de datos en paralelo para mejorar la comprensión de la selección de moléculas
- Creación de visualizaciones sólidas utilizando múltiples fuentes de datos
- Información para la selección de moléculas antes de la etapa de síntesis
- Análisis de miles de rutas en cuestión de minutos con la API SAS.
Aproveche el poder de la Puntuación de accesibilidad sintética (SAS)
La capacidad de diferenciar entre moléculas "fáciles de fabricar" y "difíciles de fabricar" es una tarea difícil, pero muy útil, por ejemplo, para priorizar compuestos en procesos de cribado virtual. Combinando el moderno modelo de aprendizaje profundo y los datos recopilados con nuestro reconocido software de planificación retrosintética, ofrecemos el servicio SYNTHIA® Puntuación de accesibilidad sintética (SAS), una herramienta aplicable al procesamiento de compuestos in silico de alto rendimiento.
En la actualidad, la química combinatoria y la modelización generativa se utilizan para construir gigantescos conjuntos de datos de compuestos [1]. Sin embargo, la síntesis real de
muchas moléculas obtenidas con tales métodos puede resultar difícil. Para abordar este problema, se utilizan medidas de accesibilidad sintética para determinar la viabilidad de las moléculas lo antes posible en el proceso de descubrimiento de fármacos.
El servicio SYNTHIA® API de SAS proporciona predicciones de dicha "complejidad molecular" en términos de número de pasos sintéticos a partir de pequeños bloques de construcción disponibles en el mercado. El modelo de aprendizaje automático en el que se basa SAS ha sido preentrenado en escenarios sintéticos obtenidos con algoritmos de SYNTHIA® Retrosynthetic Planning Tool [2], [3], [4]. Por último, nuestro producto alojado en la nube y con certificación ISO-27001 ofrece la capacidad de procesar fácilmente millones de moléculas al día y hasta mil moléculas en una sola consulta, lo que permite que la predicción del servicio SYNTHIA® SAS se utilice más comúnmente en el proceso de diseño de fármacos.
Entrada/salida para el modelo SAS
Las moléculas de entrada deben proporcionarse en el formato de texto SMILES [5], ampliamente utilizado, y el punto final de la API admite solicitudes por lotes. Los SMILES de entrada consisten en moléculas de un solo fragmento. La medida devuelta, aquí definida como Puntuación de accesibilidad sintética (SAS), es un único número flotante del rango 0-10, asignado a cada molécula de entrada correspondiente. La puntuación devuelta se aproxima al número de pasos necesarios para sintetizar la molécula utilizando bloques de construcción disponibles en el mercado. Los números más bajos (valores cercanos a 0) se devuelven a las sustancias químicas que se predice que son fáciles de fabricar (o que incluso pueden estar disponibles comercialmente). Los números más altos se devuelven cuando el modelo prevé más pasos sintéticos para obtener el compuesto solicitado. Para puntuaciones cercanas al valor máximo (10), se predice que la síntesis es extremadamente compleja (muchos pasos de reacción) o incluso inviable, por ejemplo, debido a motivos estructurales exóticos en la molécula. En general, cuanto más baja sea la puntuación, más fácil debería ser sintetizar la molécula.
En caso de que algunas de las moléculas de la solicitud no sean válidas (por ejemplo, hipervalentes, anillos incompletos, protonación inadecuada de átomos aromáticos, multifragmento), la solicitud se procesará igualmente. Las puntuaciones para tales entradas serán nulas y se devolverán comentarios apropiados junto a la estructura de la respuesta.
Características del modelo predictivo
SYNTHIA® SAS v1.0 se basa en un regresor que incluye una red neuronal convolucional gráfica (GCNN). Dicha arquitectura permite aprender una representación interna de cada molécula operando sobre su estructura gráfica en lugar de sobre descriptores moleculares precalculados [6]. En concreto, el modelo consiste en una red neuronal dirigida de paso de mensajes a nivel de enlace (D-MPNN) seguida de una red neuronal de avance (FNN). La implementación se adaptó del proyecto de código abierto Chemprop [7].
El modelo de aprendizaje automático se entrenó utilizando los resultados del módulo de Retrosíntesis automática de SYNTHIA® como valor objetivo. Se utilizó la puntuación especializada y normalizada de SYNTHIA® para reflejar el número de pasos, por ejemplo, no penalizar las reacciones no selectivas, estrategia de protecciones implícitas, contribución mínima del precio a la puntuación y sólo se utilizaron bloques de construcción pequeños como ajustes de búsqueda de SYNTHIA®. Además, se aplicó una función de suavizado para construir mejor el gradiente para las puntuaciones altas, con el objetivo de resolver mejor las moléculas difíciles de sintetizar (véase también la Fig. 1).
Los datos utilizados para el entrenamiento de los modelos de aprendizaje automático tienen 33306 moléculas en total. Se compone de moléculas conocidas (base de datos ChEMBL) [8] y pequeñas moléculas generadas combinatoriamente (GDB) [9]. La composición de los datos antes de la división entrenamiento/prueba:
- subconjunto GDB: 16081, incluyendo:
- compuestos con 1-7 átomos pesados (C, N, O, Cl, S): 7198
- compuestos con 8-9 átomos pesados (C, N, O): 8883
- subconjunto ChEMBL: 17225, incluidos:
- pequeños compuestos sintéticos seleccionados al azar: 15449
- compuestos derivados de productos naturales seleccionados al azar: 1776
El entrenamiento y la evaluación del modelo de aprendizaje automático requirieron dividir los datos en conjuntos de entrenamiento y de prueba (se utilizó la división común 80/20 entrenamiento/prueba). Además,
el conjunto de validación interna se extrajo utilizando una proporción de 9:1 del conjunto de entrenamiento y se utilizó para la optimización de los parámetros de la red.
La puntuación predicha (modelo SYNTHIA® SAS) se correlaciona con el valor objetivo basado en las puntuaciones SYNTHIA® con R2 = 0,726 y MAE = 1,1497. En la Fig. 2 se presenta un diagrama de dispersión con la línea ajustada y un diagrama de cajas que muestra la densidad/distribución de los puntos de datos.

Los resultados predichos con SYNTHIA® SAS se basan en relaciones recuperadas de conjuntos de datos (posiblemente, bastante complejos y no fáciles de captar). Esto debe tenerse en cuenta cuando se consultan moléculas nuevas a través de SYNTHIA® SAS-API. En concreto, las puntuaciones de las moléculas que no están relacionadas con el conjunto de pruebas podrían quedar fuera del denominado dominio de aplicabilidad, por lo que los resultados correspondientes podrían no ser significativos. Se trata de una limitación típica de los modelos basados en datos; no obstante, siempre es bueno recordar esta limitación para evitar una interpretación errónea de las puntuaciones obtenidas.
Casos prácticos
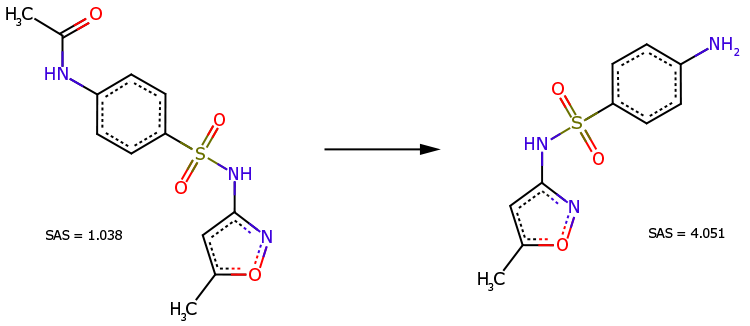
Caso 1
El derivado N-acetil del sulfametoxazol (Fig. 3, izquierda) es un precursor directo de este fármaco (Fig. 3, derecha). A pesar de su estructura química más compleja, se reconoce que el derivado es más fácil de sintetizar (SAS=1,038 es mucho menor que SAS=4,051).
Caso 2
Por otro lado, el derivado N-Boc de la adrenalina (Fig. 4, izquierda) no es un precursor directo de la adrenalina (Fig. 4, derecha). En el procedimiento típico no hay necesidad de proteger el grupo amino a lo largo de la vía de síntesis. El derivado N-Boc se reconoce correctamente como más complejo en términos de accesibilidad sintética (SAS=8,399 es mayor que SAS = 7,631). Esto concuerda con el hecho de que la adrenalina es un precursor de su derivado N-Boc.

Flujo de datos de usuario
SYNTHIA® SAS es un servicio alojado en la nube, disponible para cada cliente a través de una API RESTful. Es escalable horizontalmente y proporciona un alto rendimiento a través de un único punto de entrada API para todos los clientes. El usuario final debe proporcionar una lista de moléculas en formato SMILES y SYNTHIA® SAS devuelve una puntuación para cada una de ellas (Fig. 5). El servicio no tiene estado y está diseñado para escalar en función de la demanda.

Referencias
1. Joshua Meyers, Benedek Fabian, Nathan Brown, De novo molecular design and generative models, Descubrimiento de fármacos hoy, 26, 2021, 2707-2715. DOI
2.Software de retrosíntesis SYNTHIA®
3.Tomasz Klucznik, et al., Síntesis eficientes de dianas diversas y relevantes desde el punto de vista medicinal planificadas por ordenador y ejecutadas en el laboratorio, Chem, 4, 2018,
522-532.DOI
4. Mikulak-Klucznik, B., et al. Planificación computacional de la síntesis de productos naturales complejos, Nature, 588, 2020, 83-88. DOI
5.Daylight Chemical Information Systems, Inc.
6. Yang, K., et al. Analyzing Learned Molecular Representations for Property Prediction, Journal of chemical information and modeling, 59, 2019, 3370-3388. DOI
7.Proyecto de código abierto Chemprop
8.Base de datos ChEMBL
9.Base de datos GDB
