Nota sull'applicazione:
Punteggio di accessibilità sintetica (SAS) di Synthia
Valutazione dei punteggi di accessibilità sintetica (SAS) di migliaia di molecole virtuali in pochi minuti
Interconnettete i vostri strumenti cheminformatici con il Software di retrosintesi SYNTHIA®.
Accesso API
L'accesso API (Application Programming Interface) è disponibile per le organizzazioni che desiderano interconnettere altri strumenti cheminformatici con SYNTHIA® per un'esperienza personalizzata.
I vantaggi includono:
- Accesso alla retrosintesi completa o al Punteggio di accessibilità sintetica (SAS) API
- Visualizzazione dei dati fianco a fianco per migliorare la comprensione della selezione delle molecole
- Creazione di visualizzazioni robuste utilizzando più fonti di dati
- Informazione sulla selezione delle molecole a monte della fase di sintesi
- Analisi di migliaia di vie sintetiche in pochi minuti con l'API SAS
Sfruttare la potenza del Punteggio di accessibilità sintetica (SAS)
La capacità di distinguere tra molecole "facili da produrre" e "difficili da produrre" è un compito difficile ma di grande utilità, ad esempio per stabilire le priorità dei composti nelle pipeline di screening virtuale. Combinando il moderno modello di deep-learning e i dati raccolti con il nostro rinomato software di pianificazione retrosintetica, forniamo il servizio SYNTHIA® Punteggio di accessibilità sintetica (SAS), uno strumento applicabile all'elaborazione di composti in-silico High-Throughput.
Attualmente, la chimica combinatoria e la modellazione generativa sono utilizzate per costruire giganteschi set di composti [1]. Tuttavia, la sintesi effettiva di
molte molecole ottenute con questi metodi può essere impegnativa. Per risolvere questo problema, vengono utilizzate misure di accessibilità sintetica per determinare la fattibilità delle molecole il più presto possibile nella pipeline di scoperta dei farmaci.
Il servizio SYNTHIA® API fornisce previsioni per tale "complessità molecolare" in termini di numero di passaggi sintetici a partire da piccoli building block disponibili in commercio. Il modello di apprendimento automatico alla base di SAS è stato pre-addestrato su scenari sintetici ottenuti con gli algoritmi di SYNTHIA® Retrosynthetic Planning Tool [2], [3], [4]. Infine, il nostro prodotto, ospitato nel cloud e certificato ISO-27001, offre la possibilità di elaborare facilmente milioni di molecole al giorno e fino a un migliaio di molecole in una singola query, consentendo a SYNTHIA® SAS service prediction di essere utilizzato più comunemente nel processo di progettazione dei farmaci.
Input/output per il modello SAS
Le molecole in ingresso devono essere fornite nel formato di testo SMILES [5], ampiamente utilizzato, e l'endpoint dell'API supporta le richieste in batch. Le SMILES in ingresso sono costituite da molecole a frammento singolo. La misura restituita, qui definita Punteggio di accessibilità sintetica (SAS), è un singolo numero float compreso nell'intervallo 0-10, assegnato per ogni molecola di input corrispondente. Il punteggio restituito approssima il numero di passaggi necessari per sintetizzare la molecola utilizzando i building block disponibili in commercio. I numeri più bassi (valori prossimi allo 0) vengono restituiti alle sostanze chimiche che si prevede siano facili da produrre (o addirittura disponibili in commercio). I numeri più alti vengono restituiti quando il modello prevede più passaggi sintetici per ottenere il composto richiesto. Per i punteggi vicini al valore massimo (10), si prevede che la sintesi sia estremamente complessa (molte fasi di reazione) o addirittura irrealizzabile, ad esempio a causa di motivi strutturali esotici nella molecola. In generale, più basso è il punteggio, più facile dovrebbe essere la sintesi della molecola.
Nel caso in cui alcune delle molecole nella richiesta non siano valide (ad esempio, ipervalenti, anelli incompleti, protonazione impropria degli atomi aromatici, multi-frammento), la richiesta verrà comunque elaborata. I punteggi per tali voci saranno nulli e i commenti appropriati saranno restituiti a fianco nella struttura della risposta.
Caratteristiche del modello predittivo
SYNTHIA® SAS v1.0 si basa su un regressore che include una rete neurale convoluzionale a grafo (GCNN). Tale architettura consente di apprendere una rappresentazione interna di ciascuna molecola operando sulla sua struttura a grafo piuttosto che su descrittori molecolari precalcolati [6]. In particolare, il modello è costituito da una rete neurale con passaggio di messaggi diretto a livello di legame (D-MPNN) seguita da una rete neurale a feedforward (FN) L'implementazione è stata adattata dal progetto open-source Chemprop [7].
Il modello di apprendimento automatico è stato addestrato utilizzando i risultati del modulo di Retrosintesi automatica di SYNTHIA® come valore target. È stato utilizzato un punteggio SYNTHIA® specializzato e normalizzato per riflettere il numero di passaggi, ad esempio non penalizzando le reazioni non selettive, la strategia di protezione implicita, il contributo minimo del prezzo al punteggio e l'utilizzo di blocchi di costruzione di piccole dimensioni come impostazioni di ricerca SYNTHIA®. Inoltre, è stata applicata una funzione di smoothing per costruire meglio il gradiente per i punteggi più alti, con l'obiettivo di risolvere meglio le molecole difficili da sintetizzare (si veda anche la Fig. 1).
I dati utilizzati per l'addestramento dei modelli di apprendimento automatico contano 33306 molecole in totale. Sono composti da molecole note (database ChEMBL) [8] e da piccole molecole generate combinatoriamente (GDB) [9]. La composizione dei dati prima della divisione train/test:
- Sottoinsieme GDB: 16081, di cui:
- composti con 1-7 atomi pesanti (C, N, O, Cl, S): 7198
- composti con 8-9 atomi pesanti (C, N, O): 8883
- Sottoinsieme ChEMBL: 17225, tra cui:
- piccoli composti sintetici selezionati a caso: 15449
- composti derivati da prodotti naturali selezionati a caso: 1776
L'addestramento e la valutazione del modello di apprendimento automatico hanno richiesto la suddivisione dei dati in set di addestramento e test (è stata utilizzata una suddivisione 80/20 tra addestramento e test). Inoltre,
il set di validazione interna è stato estratto con un rapporto di 9:1 dal set di addestramento ed è stato utilizzato per l'ottimizzazione dei parametri della rete.
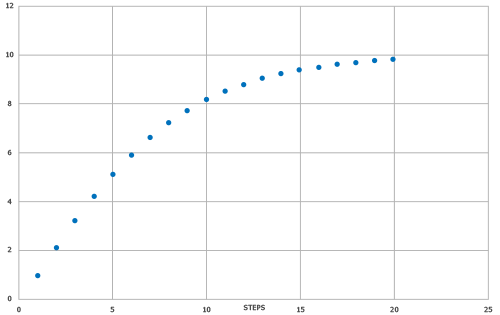
Il punteggio previsto (modello SYNTHIA® SAS) è correlato al valore target basato sui punteggi SYNTHIA® con R2 = 0,726 e MAE = 1,1497. Il grafico di dispersione con la linea adattata e il box plot che mostra la densità/distribuzione dei punti dati sono presentati nella Fig. 2.

I risultati previsti da SYNTHIA® SAS si basano su relazioni recuperate da insiemi di dati (probabilmente piuttosto complessi e non semplici da catturare). Questo aspetto deve essere preso in considerazione quando si interrogano molecole nuove tramite SYNTHIA® SAS-API. In particolare, i punteggi per le molecole che non sono correlate al set di test potrebbero non rientrare nel cosiddetto dominio di applicabilità e quindi i risultati corrispondenti potrebbero non essere significativi. Si tratta di una limitazione tipica dei modelli data-driven, tuttavia è sempre bene ricordarla per evitare un'interpretazione errata dei punteggi ottenuti.
Casi di studio
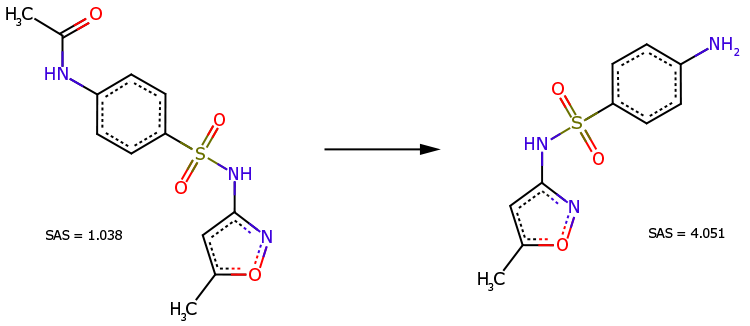
Caso 1
Il derivato N-acetilico del sulfametossazolo (Fig. 3, a sinistra) è un precursore diretto di questo farmaco (Fig. 3, a destra). Nonostante la struttura chimica più complessa, il derivato è riconosciuto come più facile da sintetizzare (SAS=1,038 è molto più piccolo di SAS=4,051).
Caso 2
D'altra parte, il derivato N-Boc dell'adrenalina (Fig. 4, a sinistra) non è un precursore diretto dell'adrenalina (Fig. 4, a destra). Nella procedura tipica non è necessario proteggere il gruppo amminico durante tutto il percorso di sintesi. Il derivato N-Boc è correttamente riconosciuto come più complesso in termini di accessibilità sintetica (SAS=8,399 è maggiore di SAS=7,631). Ciò è in linea con il fatto che l'adrenalina è un precursore del suo derivato N-Boc.

Flusso di dati utente
SYNTHIA® API è un servizio ospitato nel cloud, disponibile per ogni cliente tramite API RESTful. È scalabile orizzontalmente e fornisce un elevato throughput attraverso un unico punto di ingresso API per tutti i clienti. L'utente finale deve fornire un elenco di molecole in formato SMILES e SYNTHIA® SAS restituisce un punteggio per ciascuna di esse (Fig. 5). Il servizio è stateless e progettato per scalare in base alla domanda.

Riferimenti
1. Joshua Meyers, Benedek Fabian, Nathan Brown, De novo molecular design and generative models, Scoperta di farmaci Today, 26, 2021, 2707-2715. DOI
2.Software di retrosintesi SYNTHIA®
3.Tomasz Klucznik, et al., Efficienza delle sintesi di bersagli diversi e rilevanti dal punto di vista medico pianificate al computer ed eseguite in laboratorio, Chem, 4, 2018,
522-532.DOI
4. Mikulak-Klucznik, B., et al. Computational planning of the synthesis of complex natural products, Nature, 588, 2020, 83-88. DOI
5.Daylight Chemical Information Systems, Inc.
6. Yang, K., et al. Analyzing Learned Molecular Representations for Property Prediction, Journal of chemical information and modeling, 59, 2019, 3370-3388. DOI
7.Progetto open-source Chemprop
8. Database ChEMBL Banca dati ChEMBL
9.GDBBanca dati GDB
